DIY微调一个微信分身
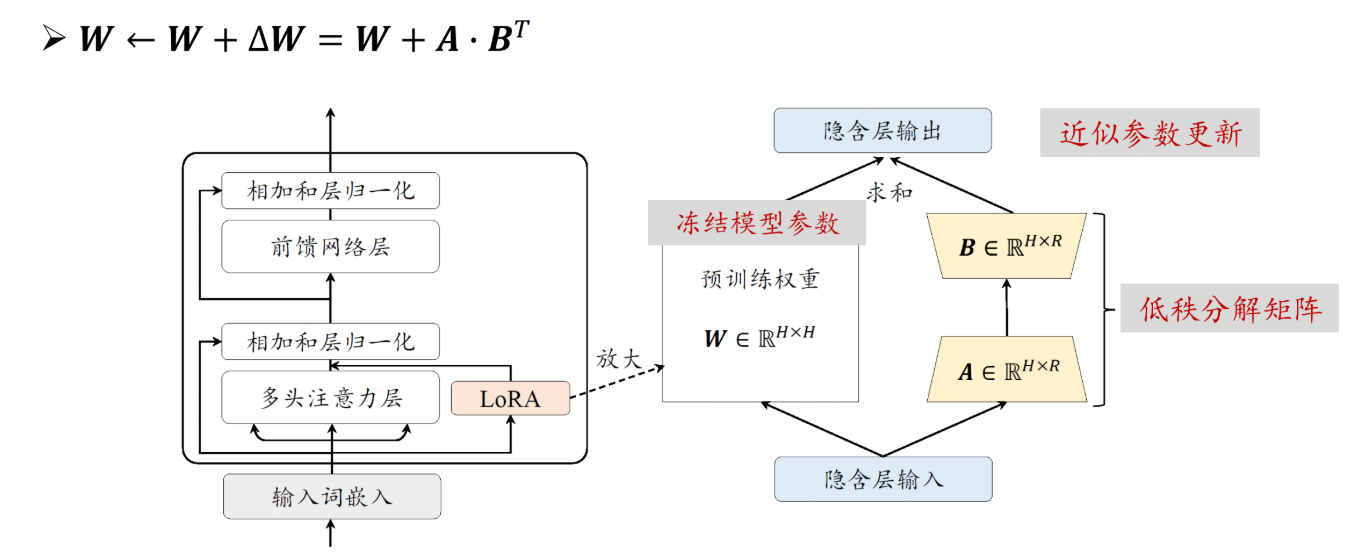
LLM微调Demo项目1.LLama-Factory环境的搭建LLaMA-Factory是一个高效、易用的大模型微调框架,集成了多种微调方法和模型支持。在CloudStudio上搭建环境的步骤如下: 首先创建实验所需的虚拟环境: 然后从GitHub拉取LLaMA-Factory仓库,安装环境依赖: 最后运行llamafactory-cli version进行验证。若显示当前LLaMA-Factory版本,则说明安装成功: 2.Lora微调原理在第一周的YOLO项目中,我们对整个网络的参数进行端到端的训练;而在大模型微调领域,由于模型参数量动辄数十亿甚至千亿级别,全参数微调的计算成本和存储成本都极其高昂。LoRA(Low-Rank Adaptation)正是为解决这一问题而提出的高效微调方法。 LoRA的核心思想源于一个重要假设:模型在适应特定任务时,权重的更新矩阵具有较低的”内在秩”(Intrinsic Rank)。基于这一假设,LoRA不直接修改预训练模型的原始权重W,而是将权重更新量ΔW分解为两个低秩矩阵的乘积:ΔW = BA,其中B∈R^(d×r)、A∈R^(r...
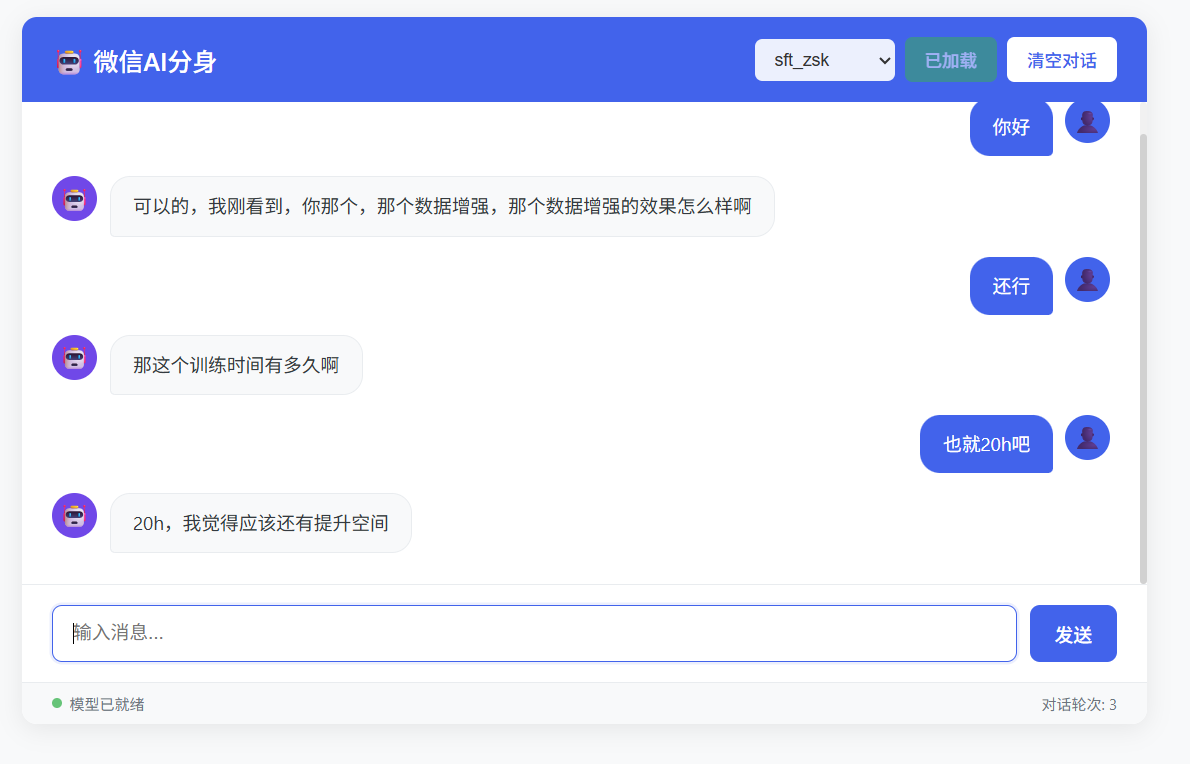
CPT-SFT-DPO实战
LLaMA-Factory 实战指南:从 CPT 到 DPO 全流程详解一、LLM 训练框架概览1.1 框架总结在开始实战前,需要明确工具定位。目前的 LLM 训练框架可以类比 CV 领域分为三个层级: 层级 CV 领域类比 LLM 领域对应 特点 典型行为 L1: 底层 PyTorch/TensorFlow搭建 ResNet/CNN Transformers, PEFT(微调), Accelerate(分布式、训练加速),DeepSpeed(分布式、训练加速), bitsandbytes(量化), TRL(DPO,PPO等强化学习),vLLM(推理加速),Torchtune(pytorch维护的一个llm库) 灵活开发 class MyModel(nn.Module): ... 手写 Training Loop L2: 中间层 YOLO, MMDetection Axolotl,SWIFT(主要支持modelscope),PaddleNLP, Unsloth 配置驱动、高效、工业级 修改 config.yaml 运行 axolotl train conf...
Pyinstaller打包YOLOv11和PyQt5项目为exe文件
1. 准备干净的环境否则会将无关的库部打包进去,导致 exe 文件动辄 1GB 以上甚至报错,建议创建一个干净的环境,只装必要的库。 2. 修改代码中的路径处理打包后的程序在运行时,会解压到一个临时目录(sys._MEIPASS)。如果在代码里写死了 model = YOLO('weights/best.pt') 或者 icon = QIcon('img/logo.png'),打包后会报错“找不到文件”。 必须在你的Qt主代码(比如 main.py)中添加并使用这个函数: 12345678910111213141516171819202122232425import sysimport osdef get_resource_path(relative_path): """ 获取资源文件的绝对路径 用于解决打包成exe后路径错乱的问题 """ if hasattr(sys, '_MEIPASS'): # PyInstaller ...
YOLO引入注意力模块
这里对自己简单的修改YOLO网络做一个记录,YOLO这个框架非常成熟(修改yolov8、v9、v11等等都是相同的方法),进行这种即插即用模块的修改非常简单,下面我会以非常典型的CBAM模块为例子。 一、注意力模块CBAM模块网上介绍的博客非常多,这里我不再赘述。源码如下,要明白的是这个模块不会改变通道数,可以理解为只矫正所学特征。所以才被归为即插即用的模块。另外需要注意这里有个输入通道的参数需要指定,要根据插入到YOLO网络位置修改。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748import torchimport torch.nn as nn class ChannelAttention(nn.Module): """Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet.&...
LLM微调理论整理
大模型训练与微调 大语言模型(LLM)的成长过程,大体可以分为三个阶段: 阶段 目标 学习方式 类比 预训练(Pretraining) 学习语言规律和知识 自监督学习 小孩学习基础语法 监督微调(SFT) 学会听懂“人类指令” 指令-回答对 老师手把手教你回答问题 对齐训练(RLHF) 学会“说得合适” 人类偏好反馈 学会在社交中说话得体 🧩 简单来理解:预训练让模型“有知识”;微调让模型“能沟通”;对齐让模型“合人意”。 一、预训练1.1 什么是预训练?1.1.1 背景与概念在大语言模型(LLM, Large Language Model)中,预训练(Pre-training) 是整个模型训练流程的第一阶段,也是最关键的一步。它的目标是让模型在大规模、无标注的文本数据上,通过自监督学习(Self-supervised Learning)的方式,掌握语言的基础规律和世界常识。这些数据通常来源于互联网网页、新闻、百科、书籍、社交媒体文本、论文等,从而使模型具备理解自然语言、生成自然语言的通用能力。 1.1.2 类比理解可以把预训练后的模型比作刚...

阳光明媚的一天
阳光明媚记得刚来成都时,高数老师给我们说在成都出太阳大家都是要发朋友圈的哈哈哈哈,开始很不理解,不就是出个太阳嘛,有啥大不了的。现在狠狠老实了,成都几乎一直是阴沉沉的天气,真没招了,出个太阳感觉人都活了!!! 已经是在民大的第四年了,难得有这么好的天气和心情,出去遛弯哈哈哈
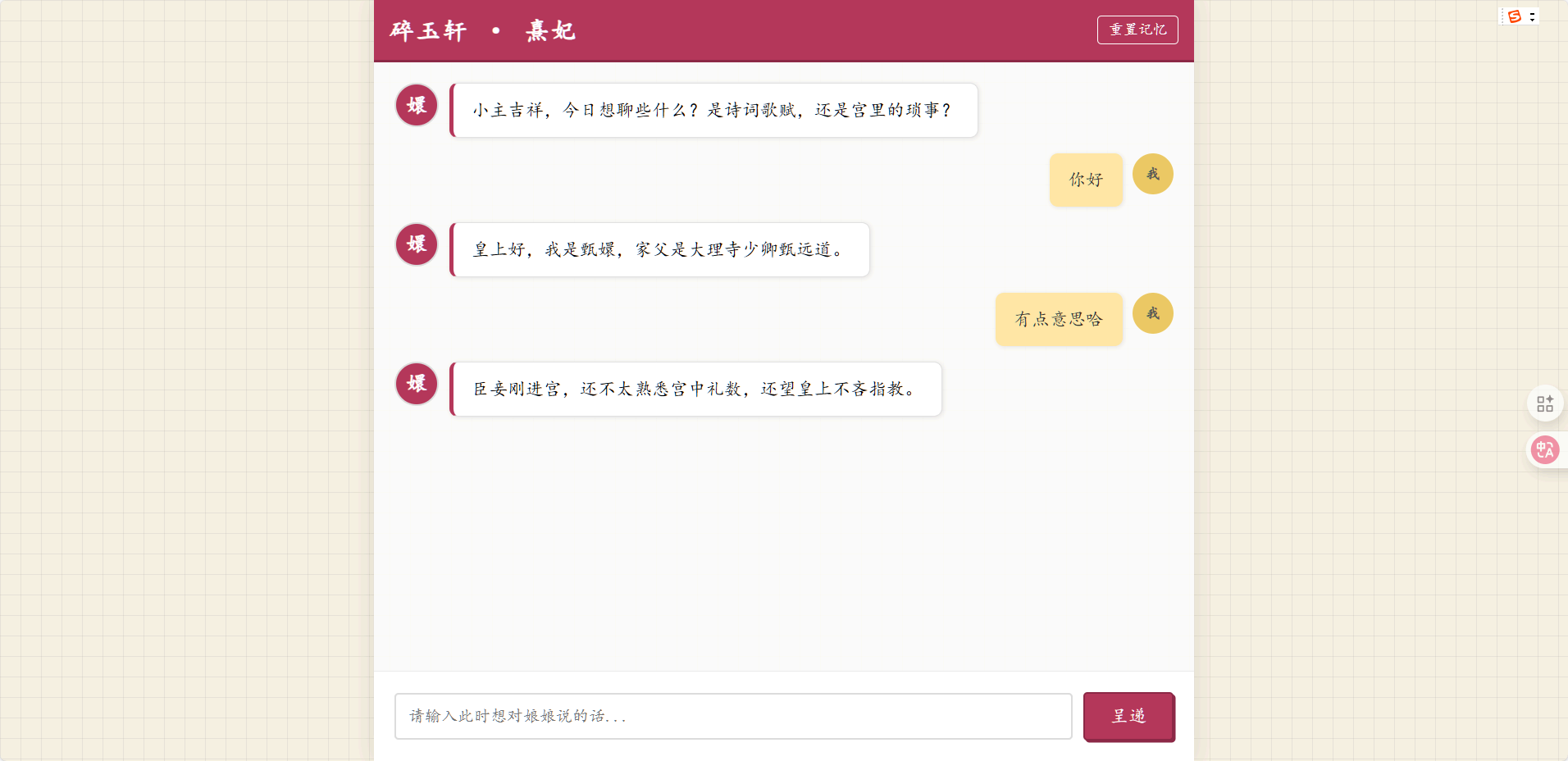
LLM微调代码实战-甄嬛机器人
实战笔记:基于 Qwen-7B LoRA 微调“Chat-甄嬛” 📌 GitHub 项目地址:甄嬛robot欢迎 Star ⭐ 和 Fork,一起探索 LLM 微调的实战之道! 🧠 核心思路与心得(写在前面)在开始敲代码之前,先整理一下关于 LLM 微调的个人理解。不同于图像分类任务(目标纯粹是追求 Accuracy 或 Precision/Recall),LLM 微调是一个“半艺术半工程”的过程: 量化指标仅供参考:Loss、PPL(困惑度)、BLEU 等指标只能反映模型拟合数据的程度,不能完全代表模型“变聪明了”或“语气像了”。 数据质量 > 数量,但量级是基础:数据的多样性和质量确实最重要,但前提是数据量要能支撑起这种多样性(勉强能训练的量级)。 数据工程的性价比: 纯人工:太耗时耗力,不可持续。 纯自动:落地的质量比较不好。 半自动(最佳实践):使用自动化工具(如 EasyDataSet)进行初筛和生成,配合人工/脚本微调。这是目前性价比最高的状态。 评测的艺术:人的感觉很主观,但也很重要。如何准备高质量的测试问题(Test Prompts)来探测模型的...
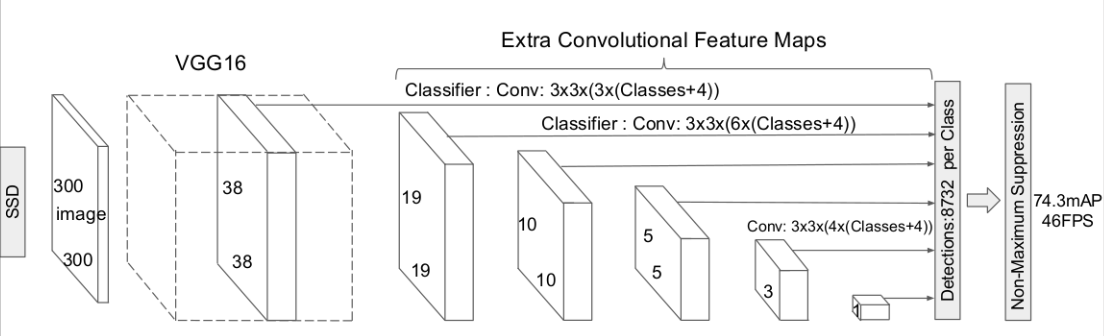
目标检测初理解
一、BaseLine1.1 整体架构大三上实训内容完成基础的目标检测任务,每张图片仅含有一个检测目标,将其框选并识别出来即可。基本的流程和图像分类一致,区别在数据集的标注上增加边界框的位置标签,以及在model的设计上使用分别使用分类头和位置偏移预测头来区别输出,最后训练时累计分类损失和位置偏移损失,再进行反向梯度传播并更新,大致示意图如下: 数据处理:将数据集标注后返回image、cls_label、loc_label(区别就在多了位置标签) 网络架构:主干CNN提取特征后分别使用分类头和边界框回归头预测 训练流程:与分类任务基本相同,主要是分别计算交叉熵损失和回归损失求和后再进行反向传播 推理预测:前向传播得到结果后,如果预测框和标签框iou大于设定的阈值就将预测结果显示出来 1.2 NMS(非极大抑制)作用:从生成的多个候选框中选择最佳的一个。出于提高目标检测召回率的目的,通常会生成数量众多的候选框,可以通过设置阈值筛选置信度低的,但仍会存在几个较高的置信度的框留下来,nms的作用就是删掉冗余的框,保留最佳的框。 原理:关键就两点,一是选择置信度大的框作为可能最优的框...

pytorch使用细节杂谈
矩阵相加: 在numpy中(2, 256) + (1, 256),会把(1, 256)直接复制上面一行变成(2, 256)然后相加,也就是广播机制,也很合理就是直接扩展维度小的相加,在XW+b中用的很多,因为b就是(1, size)的行向量要和前面做相加操作 torch.long()即向下取整 实例和类区别: 实例化的self.linear,就直接调用就好,为什我还傻乎乎的想着输入的y.reshape((-1, y.shape[-1]))是一个(时间步数*批量大小, 隐藏单元数)的二维张量,这明明和前面定义的线性层不一致 参数的requires_grad: 网络中的参数可以设置requires_grad为true还是false,要同时设置这个为true,以及将他注册到优化器中,才会在训练过程中更新参数pytorch中模型参数requires_grad的含义 death_函数 detach_是用来防止梯度积累(不是数值上的爆炸和消失),是从计算量和内存的角度考虑,因为在前向传播过程中会保存一些相关的信息,以用来反向传播,如果不分离出来每次...

Github常用命令
两种使用场景1. 从远程clone下来123456git clone git@github.com:worlds3/DCGAN.git #选择sshgit add . # 提交所有修改到缓冲区git commit -m "描述修改信息" # 提交到本地仓库git push origin main # 提交到远程仓库# 可能有需求拉取远程更新 # git pull origin main 2. 从零创建新仓库1234567891011mkdir project && cd project # 创建并进入本地文件夹git init # 初始化为git仓库touch REDME.md # 进行创建文件操作等等touch .gitignore # 这里应先建立一个 .gitignore 把忽略的文件和文件目录放进去git add . or git add <file> # 提交所有 or 部分修改到缓冲区git commit -m "修改的描述信息" # 提交到本地仓库git remote add origin git...