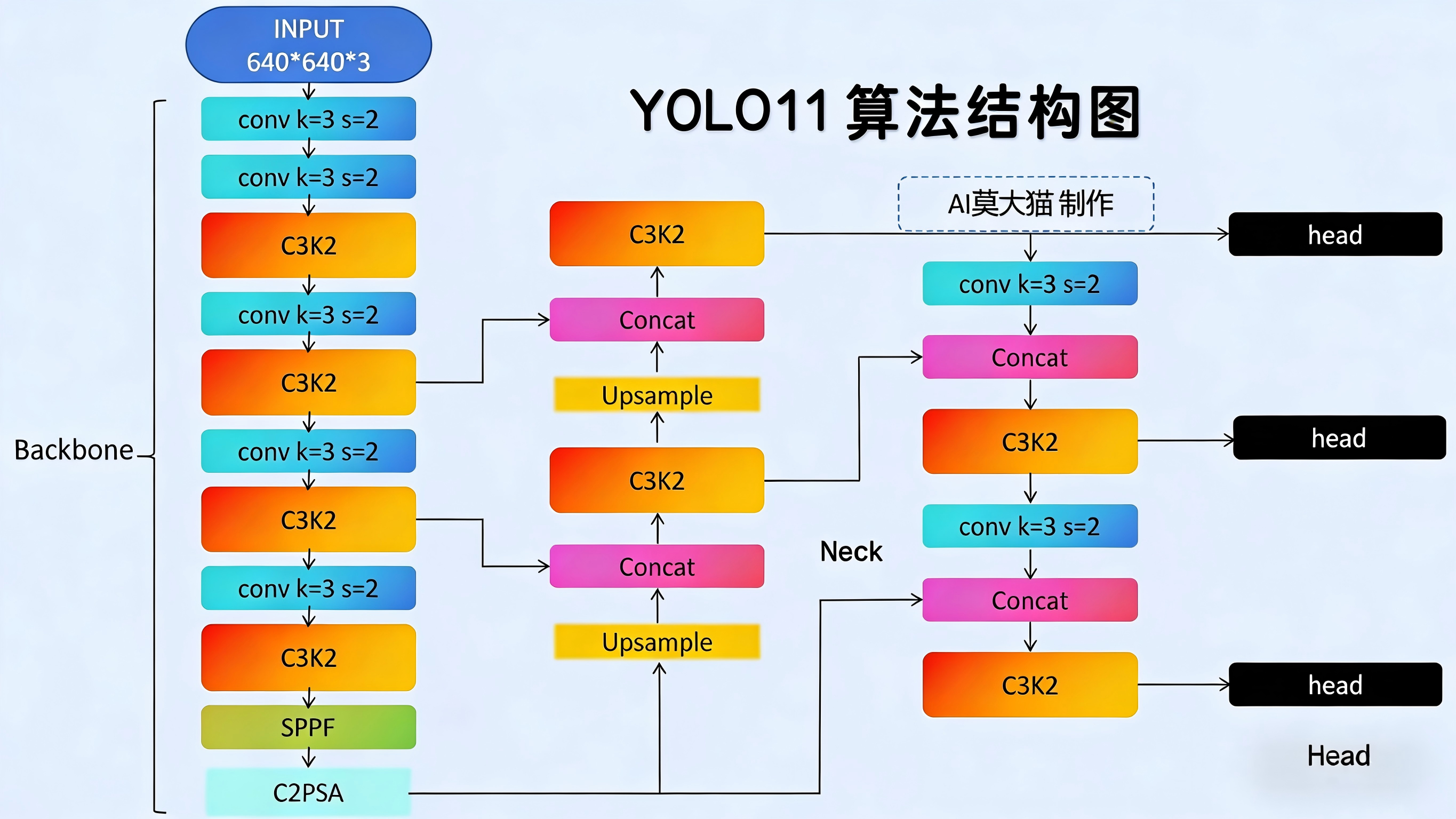
LLM微调代码实战-甄嬛机器人
实战笔记:基于 Qwen-7B LoRA 微调“Chat-甄嬛”
📌 GitHub 项目地址:甄嬛robot
欢迎 Star ⭐ 和 Fork,一起探索 LLM 微调的实战之道!
🧠 核心思路与心得(写在前面)
在开始敲代码之前,先整理一下关于 LLM 微调的个人理解。不同于图像分类任务(目标纯粹是追求 Accuracy 或 Precision/Recall),LLM 微调是一个“半艺术半工程”的过程:
- 量化指标仅供参考:Loss、PPL(困惑度)、BLEU 等指标只能反映模型拟合数据的程度,不能完全代表模型“变聪明了”或“语气像了”。
- 数据质量 > 数量,但量级是基础:数据的多样性和质量确实最重要,但前提是数据量要能支撑起这种多样性(勉强能训练的量级)。
- 数据工程的性价比:
- 纯人工:太耗时耗力,不可持续。
- 纯自动:落地的质量比较不好。
- 半自动(最佳实践):使用自动化工具(如 EasyDataSet)进行初筛和生成,配合人工/脚本微调。这是目前性价比最高的状态。
- 评测的艺术:人的感觉很主观,但也很重要。如何准备高质量的测试问题(Test Prompts)来探测模型的边界,本身就是一门学问。
1. 项目目标
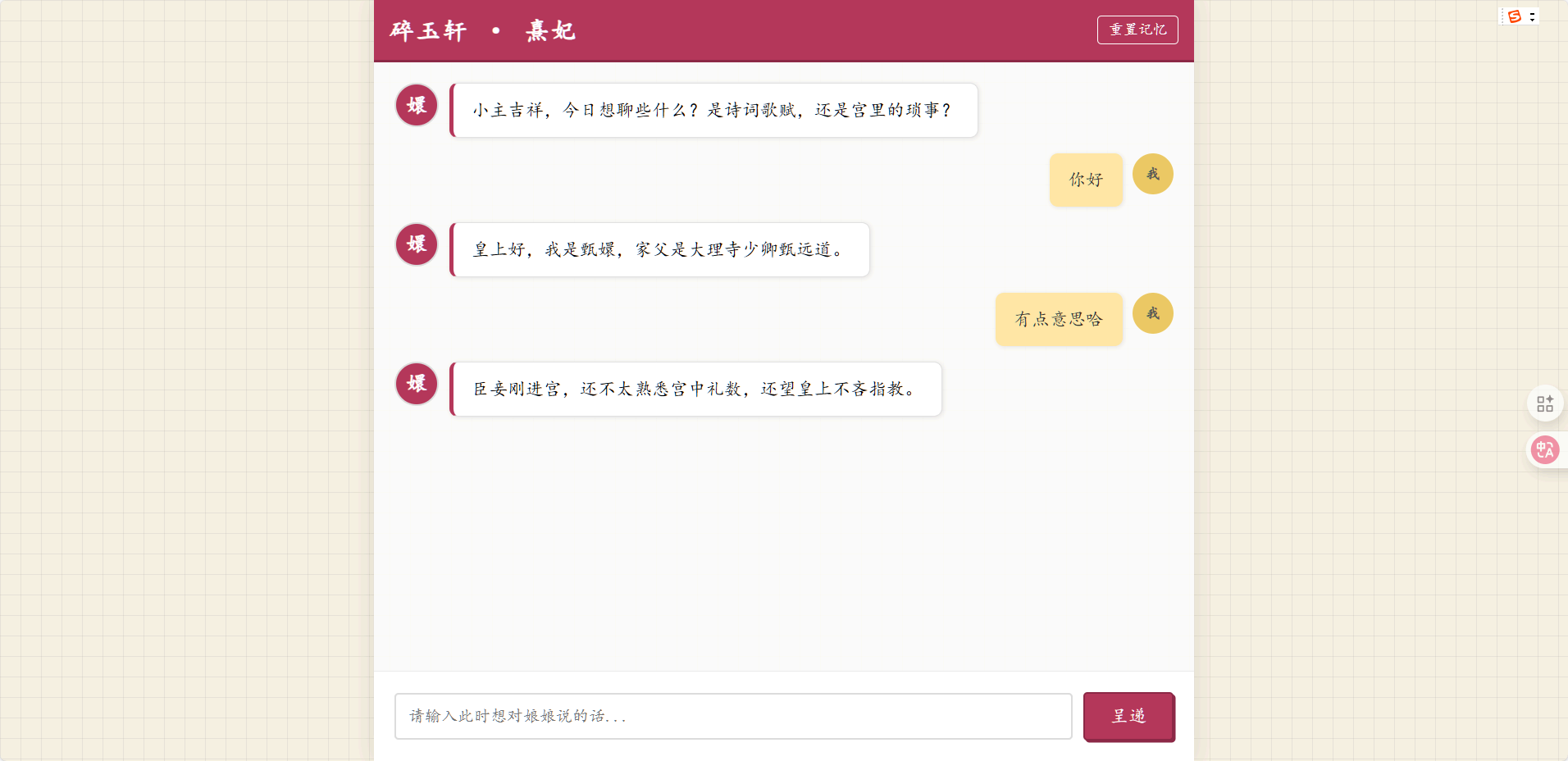
以 Github 开源项目为例子训练一个 Chat-甄嬛,利用《甄嬛传》剧本中所有关于甄嬛的台词和语句,基于 Qwen-7B 进行 LoRA 微调,打造一个模仿甄嬛语气的聊天机器人。
💡【为什么是 LoRA?】
在实际生产环境中,全量微调(Full Fine-tuning)一个 7B 以上的模型不仅需要昂贵的 A100 集群,还容易导致模型“灾难性遗忘”(即学了甄嬛的语气,忘了通用的知识)。
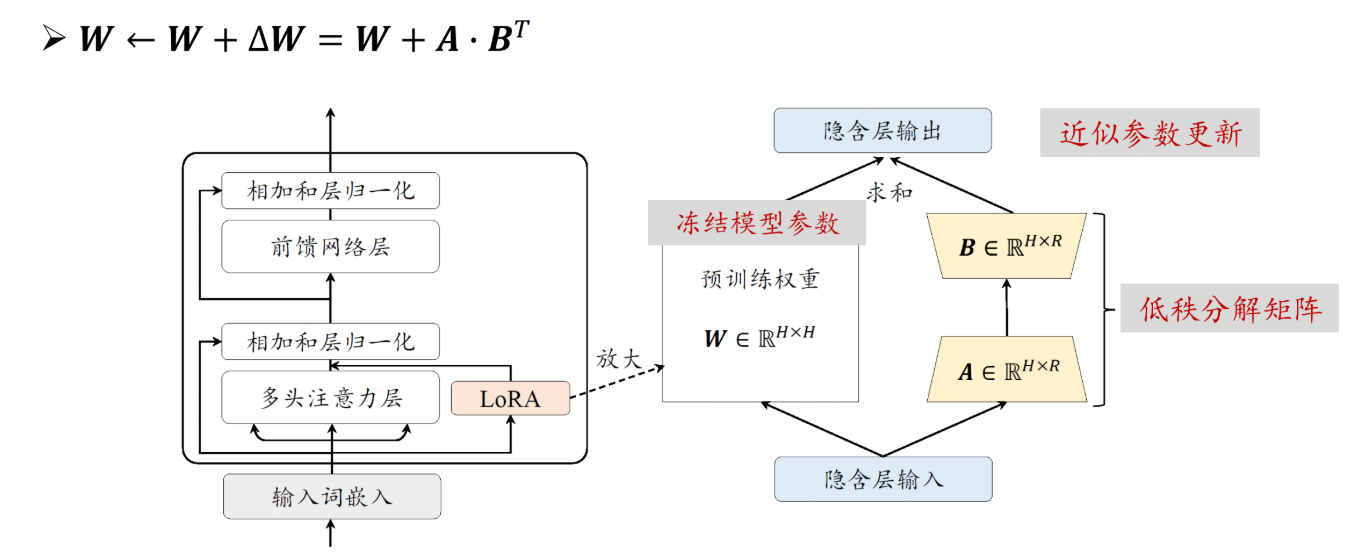
LoRA (Low-Rank Adaptation) 的本质是在大模型原有的参数旁“外挂”两个很小的矩阵(A和B)。我们只训练这两个小矩阵(参数量通常<1%),既大幅降低了显存需求(消费级显卡可跑),又保留了基座模型的通用能力。这是目前工业界性价比最高的微调方案。
2. 环境与模型准备
2.1 环境配置
首先 pip 换源并安装必要的依赖库
1 | 升级pip |
2.2 模型下载
使用 modelscope 中的snapshot_download函数下载 Qwen-7B-Chat 模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在代码路径下新建 download.py 文件并在其中输入以下内容,download.py执行下载,模型大小为 15 GB,下载模型大概需要 10~20 分钟。
1 | import torch |
2.3 基座模型测试
微调前,先确认基座模型能正常工作。新建 trans.py,测试下载的模型。
1 | import torch |
需要根据自己的代码目录更换环境,运行后能回答问题就没问题

3. 数据工程(核心难点)
3.1 补充环境
微调训练需要额外的库:
1 | pip install transformers==4.35.2 |
3.2 深度理解:SFT数据构建
在开始构建数据前,我们需要厘清几个常被混淆的概念。在 SFT (Supervised Fine-Tuning) 的大框架下,我们根据微调的目的将其细分为两个既独立又常常结合的子集:指令微调(IT)和领域微调(DSFT),它们不是互斥的,是 格式与内容 的关系。其实大多数都不用用区分这么细,因为在微调的时候肯定是一方面学习领域表达术语、逻辑等内容,一方面也要约束模型输出的格式。我们这里的甄嬛体微调赋予模型“甄嬛人格”并遵循指令
(1)指令微调(Instruction Tuning):
| 维度 | 描述 | 核心目标 |
|---|---|---|
| 目的 | 培养模型遵循指令、理解用户意图、按照指定的格式输出的能力。 | 让模型“听得懂话”、“按要求做事”。 |
| 关注点 | 交互格式、逻辑结构、约束遵循。 | 是否能按 JSON 输出、是否能按照步骤推理、是否能进行多轮对话。 |
| 核心地位 | LLM 微调的核心。它是模型从基础大模型(Base Model)进化到 AI 助手的关键。 | 即使是领域微调,也需要依赖指令微调的能力作为操作接口。 |
- 格式:
1 | { |
这是 Qwen-7B-Chat 这种 Chat 模型的关键能力来源。
(2)领域微调(Domain SFT)
目的: 注入领域习惯、术语和逻辑,让模型学会某领域的风格、术语和表达方式。换句话说:领域微调决定“模型像谁说话、懂什么领域”。
误区警示: SFT 对“注入海量知识”的效果其实很有限。 如果你有1G的飞机维修手册 PDF,光靠 SFT,模型很难把所有维修参数背下来且不产生幻觉。
正确认知: SFT 更多是学会“飞机维修专家的说话语气、术语的使用、推理的逻辑”。真正要注入海量知识,通常需要 CPT(增量/继续预训练) 或者更实际的 RAG(检索增强生成)。SFT 在这里的角色是让模型更擅长配合 RAG 系统。
💡【SFT与RAG】
个人理解其实做SFT其实和RAG是相辅相成、互为一体的,都需要从拿到的语料中清洗出来高质量的数据。真实项目里面拿到的语料一定是五花八门的,数据格式可能有PDF、word、TXT、Markdown,xlsx更麻烦的是图片/图片型PDF(甚至还有水印)。语料中又会有公式,表格等等,不限于简单的纯文本。
面对这种复杂的语料、怎么从得到纯文本、公式、图片怎么处理、如何切出语义连续的文本块以供使用,这些问题无论做RAG还是SFT都是要共同面对一的,目标就是切出来长度合适、语义连续的文本块,RAG对文本块进行向量化入库,SFT需要用这个文本块做指令对,这个过程纯人工的工作量太浩大了, 而目前现成的工具一套式流程做出来的数据质量肯定是不佳的,所以还是要会到半工具半人工校正的方式。
3.3 数据构建策略:从“剧本”到“指令”
LLM 微调的核心是 指令微调(Instruction Tuning)。我们需要将原始剧本转化为 Instruction - Input - Output 的格式。
对于本项目,由于数据源主要是剧本台词,结构相对简单(角色—台词):
1 | 第2幕 |
处理逻辑(Regex/脚本):
- 提取角色和对话内容。
- 构建对话流。
- 转换为 JSON 训练格式。
每一句都有人物及对应的台词,所以就可以很简单的正则匹配就将这些数据处理成对话的形式,如下:
1 | [ |
最后再把这种对话QA将其整理成 json 格式的数据,构造纯 QA 风格,这里的input也是可以省略的,直接用instruction做输入,因为这里是微调出一个甄嬛风格的聊天助手,本质是要一个QA对学习说话风格。
1 | [ |
【为什么input字段可以留空?】
在标准的 Alpaca 训练格式中,Instruction 代表任务指令,Input 代表任务处理的对象(上下文),Output 是答案。例如:“把这句话翻译成英文”(Instruction)+ “今天天气真好”(Input)。
但这个跟选择微调的模型有关,在输入到模型中去时会转换为ChatML格式,这个也是比较主流的格式,Qwen-chat系列中用的就是这个,而Llama 2 Chat就不同,需要按照选择的模型进行处理:
2
3
4
5
6
7
|system|>
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.(qwen的默认系统提示词) 可以修改为“在你要扮演皇帝身边的女人--甄嬛”
<|user|>
小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子...
<|assistant|>
嘘——都说许愿说破是不灵的。
2
3
4
5
6
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
你好 [/INST]而ChatML格式在处理的时候,会把instruction + input拼接到 user prompt中去。 所以其实某个字段留空并不影响,只要能表述清楚意思即可。在训练的时候,直接设置system prompt为要扮演的角色,所以直接使用甄嬛的QA对,让模型学习这个对话的风格语气即可达到微调的效果。在下面的训练代码中也有所体现。
3.4 补充内容—-如何从复杂语料中构建高质量数据集?
大部分教程直接提供现成的数据集,包括我们目前的案例也是直接给出的微调数据的json文件,这里附录会说明如何使用社区中维护的非常不错的工具来做初版的数据集,这里先只说思路。
在真实的落地项目中,我们面对的往往是堆积如山的 PDF、Word、Markdown复杂语料。数据准备往往占据了 70% 的工作量,且数据质量直接决定微调效果的上限。各种微调方法主要是节省显存的工程手段,数据才是灵魂。
问题:完全人工标注质量高但太慢,时间和精力消耗太高;完全自动化(丢给GPT直接生成或者用集成的工具)容易产生幻觉或逻辑断层,生成数据的质量堪忧, 针对不同场景,可以尝试不同的构建方法:
方案一:开源神器EasyDataSet
💡【工具优势】
- 集成 MinerU: 它内置了强大的 PDF 解析能力(基于 MinerU),即使是带有复杂公式、表格甚至扫描图片的 PDF 也能较好地转化为 Markdown。
- 提供常用分块: 将长文档切分成适合模型阅读的片段。
- 内置 LLM 校正: 它不仅仅是提取文本,还能调用大模型对提取内容进行清洗、QA 对生成。
这个工具已经是llm微调社区中维护的非常好的一个工具,在没有追求特别高质量的数据情况下,可以先选用这个工具作为demo,后续再进行人工的调整。
- 工具辅助:使用 EasyDataSet 等工具集成 MinerU(解析PDF)+ LLM(清洗切分),快速生成初版数据。
- 人工/脚本介入:
- 正则清洗:去除剧本中的动作描写(如“转身离去”),只保留对话。
- 坏例剔除:人工快速浏览,删掉逻辑不通的自动生成样本。
- CoT 增强:对于复杂的领域知识,需人工手写少量“思维链”样本作为种子,再让大模型模仿生成。
方案二:利用各种工具搭建自己的处理的PipeLine
对数据质量有更高要求,或者 EasyDataSet 无法满足特定的复杂文档,则可以拆解使用不同的工具,自己搭建一个更精细的 Pipeline:
高精度解析: 单独使用MinerU 或其他的OCR、专业文档转换工具,将复杂语料(保留标题层级、表格结构)转为高质量 Markdown。
多模态理解: 对于文档中的工程图、流程图,利用 Qwen2.5-VL 或 GPT-4o 进行视觉理解并生成文字描述。
自定义切块:根据自己的需求和业务逻辑,定制化的用脚本实现切块的逻辑
数据生成:
编写合适的 Prompt,让最强模型(Claude 4.5 Sonnet / Gemini3 Pro等等)基于文档切片执行以下任务:
- 提取最有价值的 10~25 个问题对(覆盖从初级到专家难度)。
- 生成包含 思维链 (CoT) 的详细答案。
- 输出严格的 JSON 格式数据,最后人工再检查。
4. 模型训练和推理
4.1 模型训练
这一步,使用peft库来实现lora微调基本是模板式的代码,修改路径后直接训练即可。
【补充Lora实战中的细节,模型最终输入形式】
模型无法直接理解 JSON,我们需要将其转换成模型训练时的Prompt Template(模版格式)并进行 Tokenization(分词)。正如上所说,Qwen-7B使用的是Chat-ML格式。代码把 instruction 和 input 拼在一起,变成用户说的话。同时,它修改了 system prompt为甄嬛人设,得到如下的模板格式
2
3
4
5
6
7
现在你要扮演皇帝身边的女人--甄嬛.<|im_end|>
<|im_start|>user
小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——<|im_end|>
<|im_start|>assistant
嘘——都说许愿说破是不灵的。<|im_end|>
<|endoftext|>再进行编码输入到模型里面中,具体的流程举个例子:
原始数据 (Alpaca):
Instruction: “你好”
Input: “”
Output: “我是甄嬛”
处理过程:
- 格式化 (Format): “<|im_start|>system\n你要扮演甄嬛<|im_end|>\n<|im_start|>user\n你好<|im_end|>\n<|im_start|>assistant\n我是甄嬛<|im_end|>”
- 编码 (Tokenize): Input_ids: [System IDs] + [User IDs] + [Assit IDs]
- 制作标签 (Labeling): Labels: [-100, …, -100] + [-100, …, -100] + [Assit IDs] (System部分不学) (User部分不学) (只学Output)
- 输入模型 (Training): Model(input_ids) -> 计算出的 Logits Loss(Logits, Labels) -> 只有 Assit 部分产生 Loss -> 反向传播
1 | from datasets import Dataset |
等待训练完成即可:
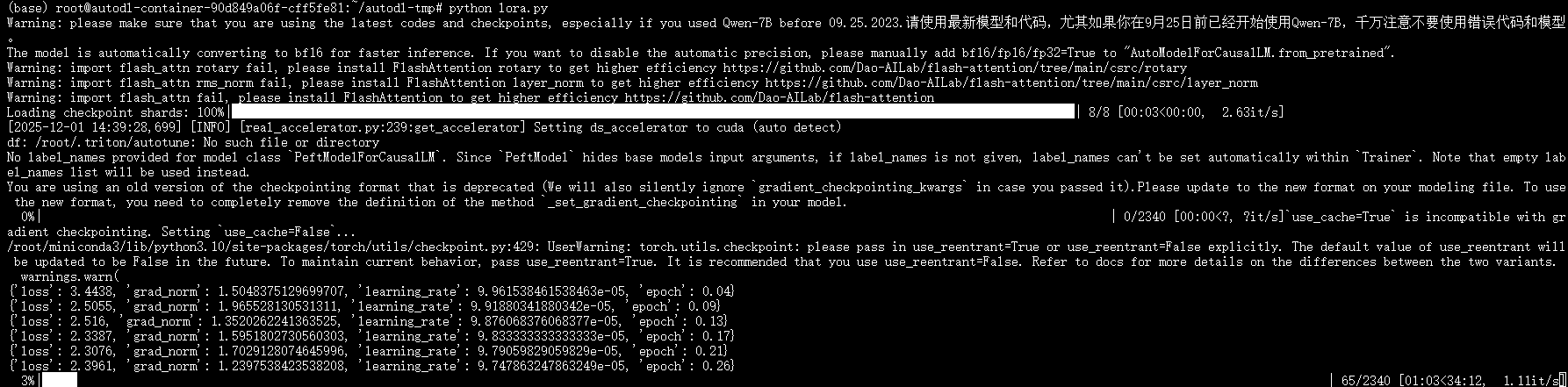
4.2 加载与推理测试
训练大概会需要 20 ~ 30 分钟的时间,训练完成之后会在output目录下生成lora模型。可以使用以下代码进行测试:
1 | import torch |
5. 模型评估
微调完成后,仅凭人工对话评测的“感觉”来对模型进行评估的过于主观。我们需要结合更客观的方法来验证模型是否真的学会了“甄嬛体”,以及是否出现了“灾难性遗忘”。即客观指标 +人工的评分
5.1 量化指标
1. 验证集 Loss (Validation Loss)
在目前的训练代码中,目前只用到了训练集。理论上,必须划分出 10% 的数据作为验证集(Validation Set),这部分数据不参与训练,观察Train loss 和 val loss。两个loss主要用于监测是否过拟合(Train降Val升)或欠拟合。只要 Loss 正常下降并收敛即可,具体数值大小在不同数据集间没有可比性。
2. 文本重合度指标 (BLEU & ROUGE)
这是传统 NLP 的评估指标。
- BLEU: 看模型生成的词有多少在标准答案里出现过(注重精确度P)。
- Perplexity:语言建模任务中常用,越低越好,代表模型越“理解”数据
- ROUGE: 看标准答案里的词有多少被模型生成出来了(注重召回率R)。
- 注:对于角色扮演,这三个指标仅供参考,因为甄嬛可以说“本宫乏了”,也可以说“臣妾身体不适”,意思一样但 BLEU 分数可能很低。
5.2 构建评测集进行打分
正如前面所说,“怎么准备问题”是关键。我们需要构建一个高质量的测试集(Test Set),该集合不参与训练。
方案 A:LLM-as-a-Judge (大模型裁判)
用 GPT-5 或 Gemini3 pro当裁判。
- Input: 用户问题 + 微调模型的回答 + 标准答案(可选)。
- Prompt: “你是一个剧本专家。请评估以下回答是否符合‘甄嬛’的语气特点(清冷、聪慧、古风)。请从 1-5 分打分,并给出理由。”
- 优点:自动化、速度快、比 BLEU 更懂语义。
方案 B:人工主观评估 (Human Eval)
虽然主观,但肯定是必不可少的。重点关注以下维度:
- 语气模仿度 (Style):是否还有“AI味”?是不是太客气了?(甄嬛应该是有锋芒的)
- 知识幻觉 (Hallucination):有没有胡编乱造剧情?
- 逻辑连贯性:多轮对话后是否还能记住自己是甄嬛?
5.3 补充内容—评估微调效果
LLM微调的评估就必须得人工用高级LLM打分的方式等主观的方式,因为特别是生成任务,量化的指标大多都是按字重叠度,这种方式对比较灵活的生成任务并不是特别合适。因为语言表达的不同但生成的意思是一致的情况是多数。但如果是机器翻译、文本分类等等用F1、ACC等指标即可,所以针对不同的微调目的,评估方式也不同:
✅ 精调任务能力:判断模型是否更好完成分类、问答、摘要、代码生成等任务。
✅ 领域适应:关注模型是否更懂特定领域(如医疗、法律、金融等)的语言和逻辑。
✅ 部署优化:比如用LoRA做高效微调,希望在保证精度的前提下减少显存/推理时间。
技术指标评估:量化模型效果
📌 通用指标
训练/验证 Loss:基础指标。验证 loss 稳定下降,说明模型没过拟合。
Perplexity(困惑度):语言建模任务中常用,越低越好,代表模型越“理解”数据。
📌 微调情感、文本分类任务
Accuracy、Precision、Recall、F1-Score、AUC 等传统指标
📌 生成任务(问答/摘要/代码等)
BLEU / ROUGE / METEOR:衡量生成文本和参考答案的相似度
人工评估维度,设计测试问题来从多个维度进行评估:
相关性(回答是否切题)
流畅性(语言是否自然)
事实正确性(有没有瞎编)
多样性(避免重复答复)
附录1—easy dataset使用
安装 Easy Dataset
方法一:使用安装包
如果操作系统为 Windows、Mac 或 ARM 架构的 Unix 系统,可以直接前往 Easy Dataset 仓库下载安装包:https://github.com/ConardLi/easy-dataset/releases/latest
方法二:使用 Dockerfile
- 从 GitHub 拉取 Easy Dataset 仓库
1 | git clone https://github.com/ConardLi/easy-dataset.git |
- 构建 Docker 镜像
1 | docker build -t easy-dataset . |
- 运行容器
1 | docker run -d \ |
方法三:使用 NPM 安装
- 下载 Node.js 和 pnpm
前往 Node.js 和 pnpm 官网安装环境:https://nodejs.org/en/download | https://pnpm.io/
使用以下代码检查 Node.js 版本是否高于 18.0
1 | node -v # v22.14.0 |
- 从 GitHub 拉取 Easy Dataset 仓库
1 | git clone https://github.com/ConardLi/easy-dataset.git |
- 安装软件依赖
1 | pnpm install |
- 启动 Easy Dataset 应用
1 | pnpm build |
控制台如果出现以下输出,则说明启动成功。打开浏览器访问对应网址,即可看到 Easy Dataset 的界面。
1 | > easy-dataset@1.2.3 start |
示例数据下载
本教程准备了一批互联网公司财报作为示例数据,包含五篇国内互联网公司 2024 年二季度的财报,格式包括 txt 和 markdown。可以使用 git 命令或者直接访问仓库链接下载。
1 | git clone https://github.com/llm-factory/FinancialData-SecondQuarter-2024.git |
数据均为纯文本数据,如下为节选内容示例。
快手二季度净利润增超七成,CEO程一笑强调可灵AI商业化
8月20日,快手科技发布2024年第二季度业绩,总营收同比增长11.6%至约310亿元,经调整净利润同比增长73.7%达46.8亿元左右。该季度,快手的毛利率和经调整净利润率均达到单季新高,分别为55.3%和15.1%。值得一提的是,针对今年加码的AI相关业务,快手联合创始人、董事长兼CEO程一笑在财报后的电话会议上表示,可灵AI将寻求更多与B端合作变现的可能性,也会探索将大模型进一步运用到商业化推荐中,提升算法推荐效率。
线上营销服务贡献近六成收入,短剧日活用户破3亿
财报显示,线上营销服务、直播和其他服务(含电商)收入依然是拉动快手营收的“三驾马车”,分别占总营收的56.5%、30.0%和13.5%。线上营销服务收入由2023年同期的143亿元增加22.1%至2024年第二季度的175亿元,财报解释主要是由于优化智能营销解决方案及先进的算法,推动营销客户投放消耗增加。
微调数据生成
创建项目并配置参数
- 在浏览器进入 Easy Dataset 主页后,点击创建项目
- 首先填写项目名称(必填),其他两项可留空,点击确认创建项目
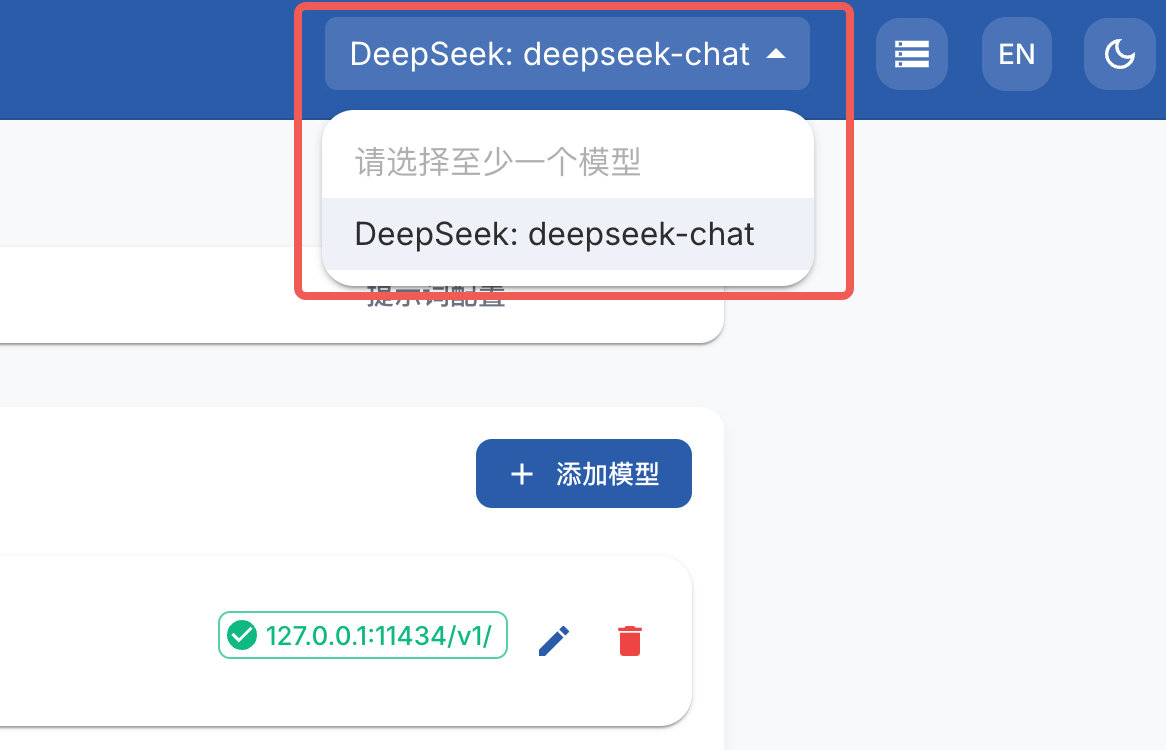
- 项目创建后会跳转到项目设置页面,打开模型配置,选择数据生成时需要调用的大模型 API 接口
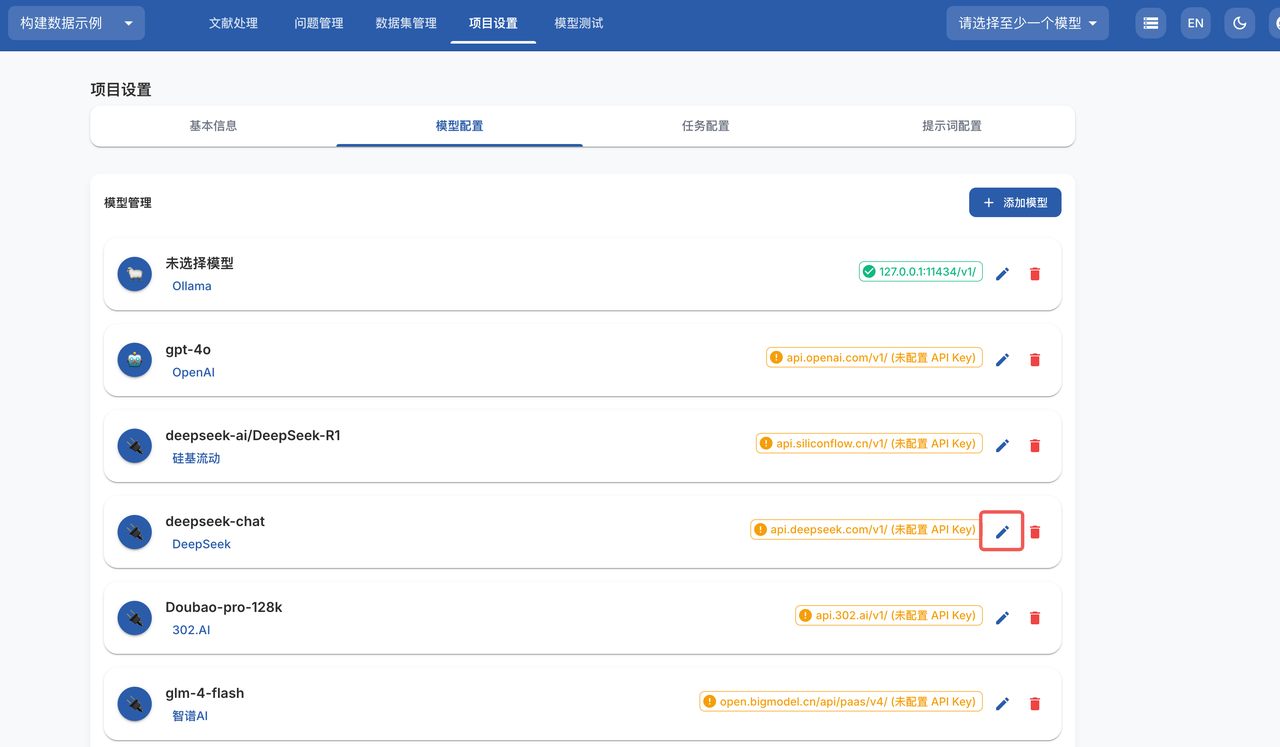
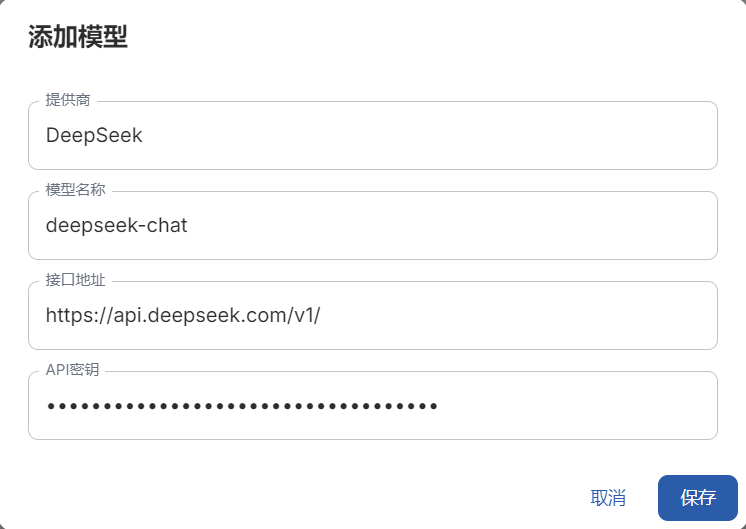
- 这里以 DeepSeek 模型为例,修改模型提供商和模型名称,填写 API 密钥,点击保存后将数据保存到本地,在右上角选择配置好的模型
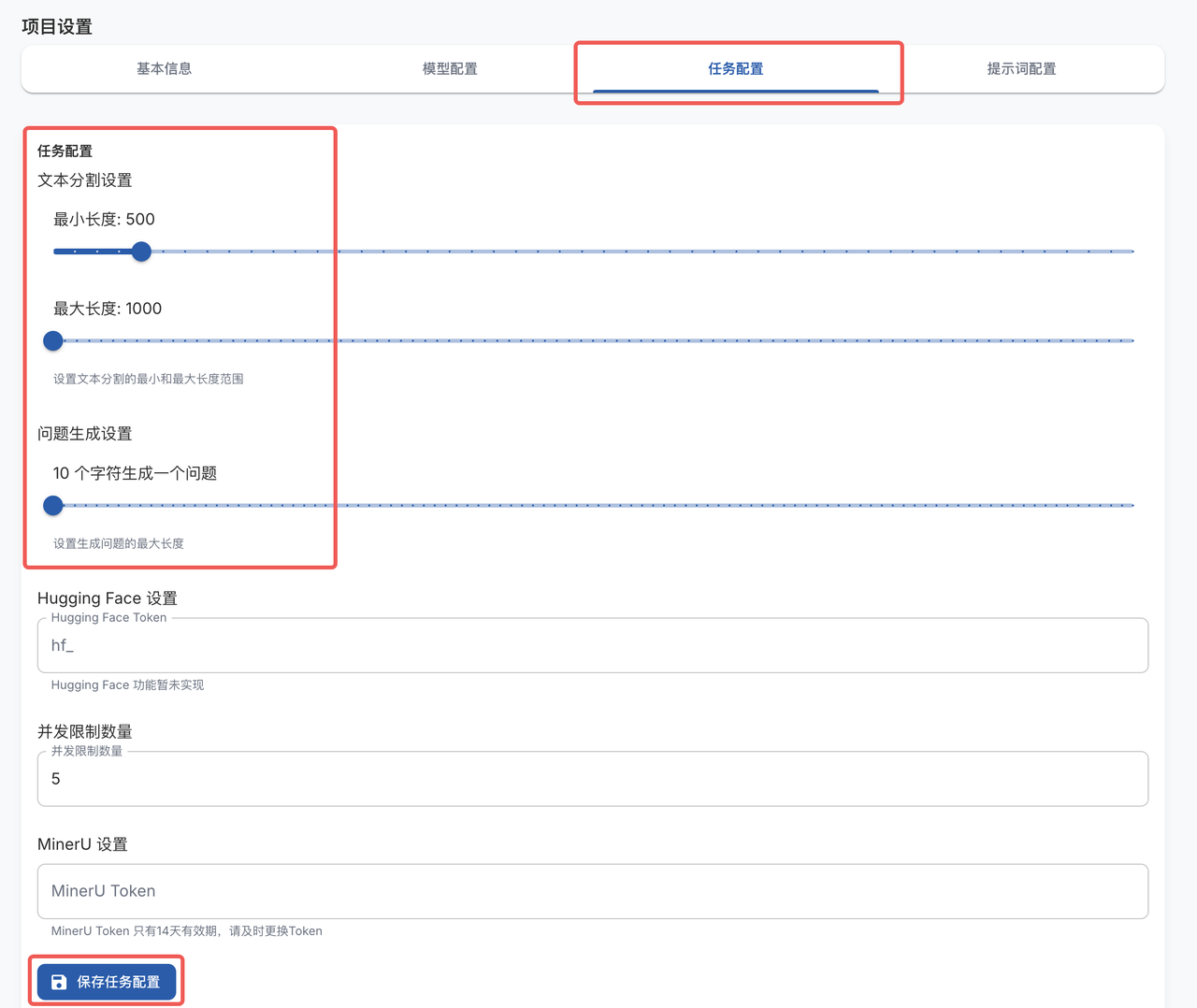
- 打开任务配置页面,设置文本分割长度为最小 500 字符,最大 1000 字符。在问题生成设置中,修改为每 10 个字符生成一个问题,修改后在页面最下方保存任务配置
处理数据文件
- 打开文献处理页面,选择并上传示例数据文件,选择文件后点击上传并处理文件
- 上传后会调用大模型解析文件内容并分块,耐心等待文件处理完成,示例数据通常需要 2 分钟左右
生成微调数据
- 待文件处理结束后,可以看到文本分割后的文本段,选择全部文本段,点击批量生成问题
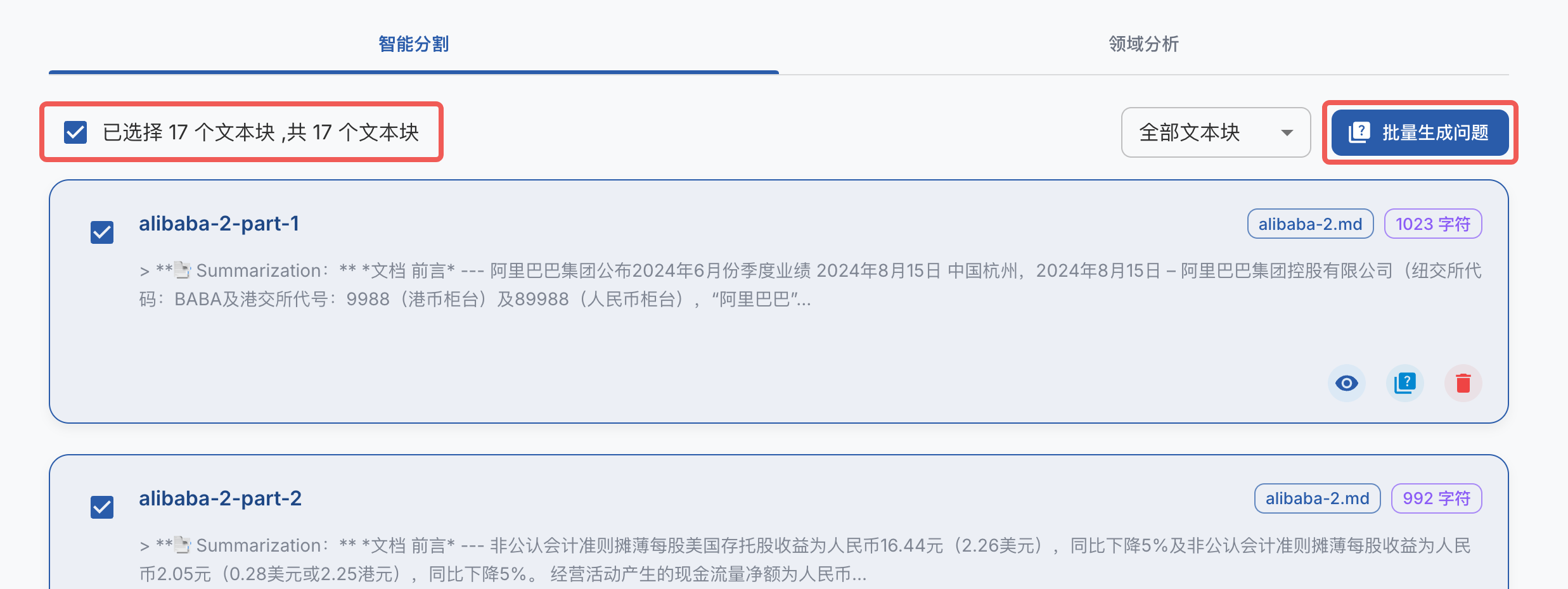
- 点击后会调用大模型根据文本块来构建问题,耐心等待处理完成。视 API 速度,处理时间可能在 20-40 分钟不等
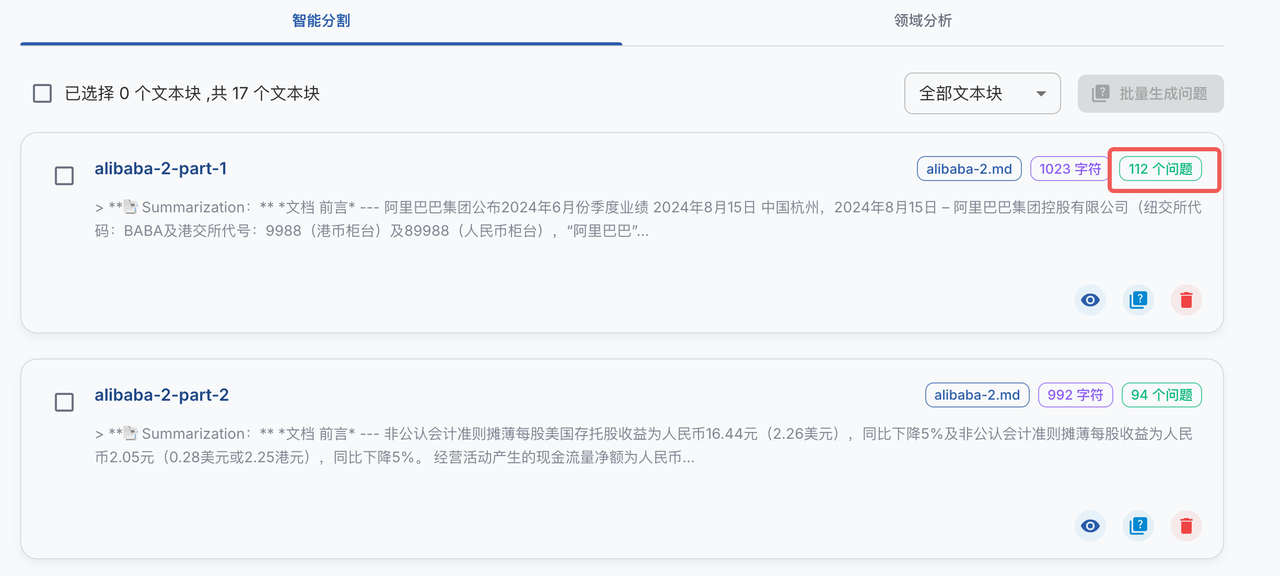
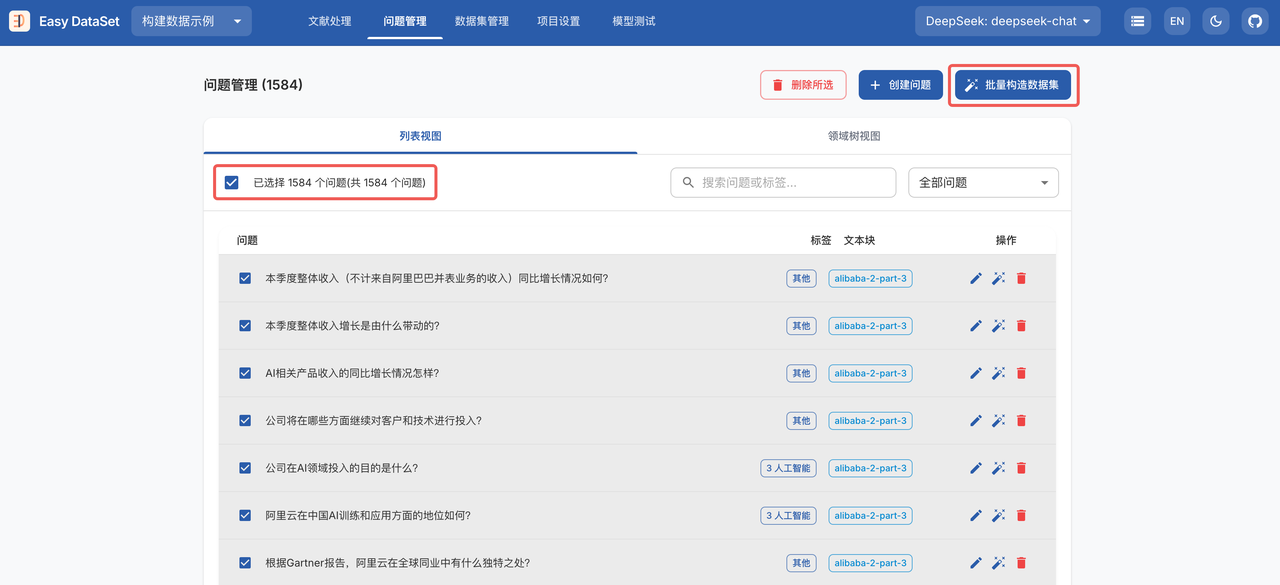
- 处理完成后,打开问题管理页面,选择全部问题,点击批量构造数据集,耐心等待数据生成。视 API 速度,处理时间可能在 20-40 分钟不等
如果部分问题的答案生成失败,可以重复以上操作再次生成。
导出数据集
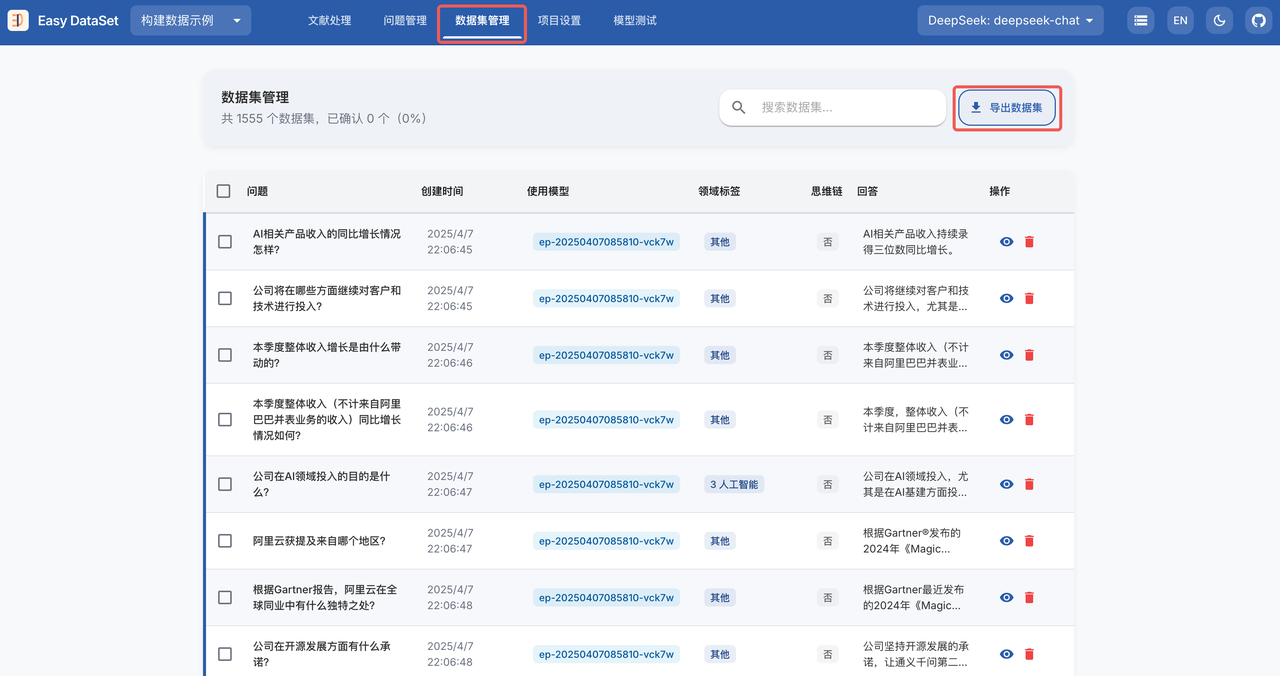
- 答案全部生成结束后,打开数据集管理页面,点击导出数据集
- 在导出配置中可以选择导出本地使用,也可以直接选择在 LLaMA Factory 中使用,点击更新 LLaMA Factory 配置,即可在对应文件夹下生成配置文件,点击复制按钮可以将配置路径复制到粘贴板。
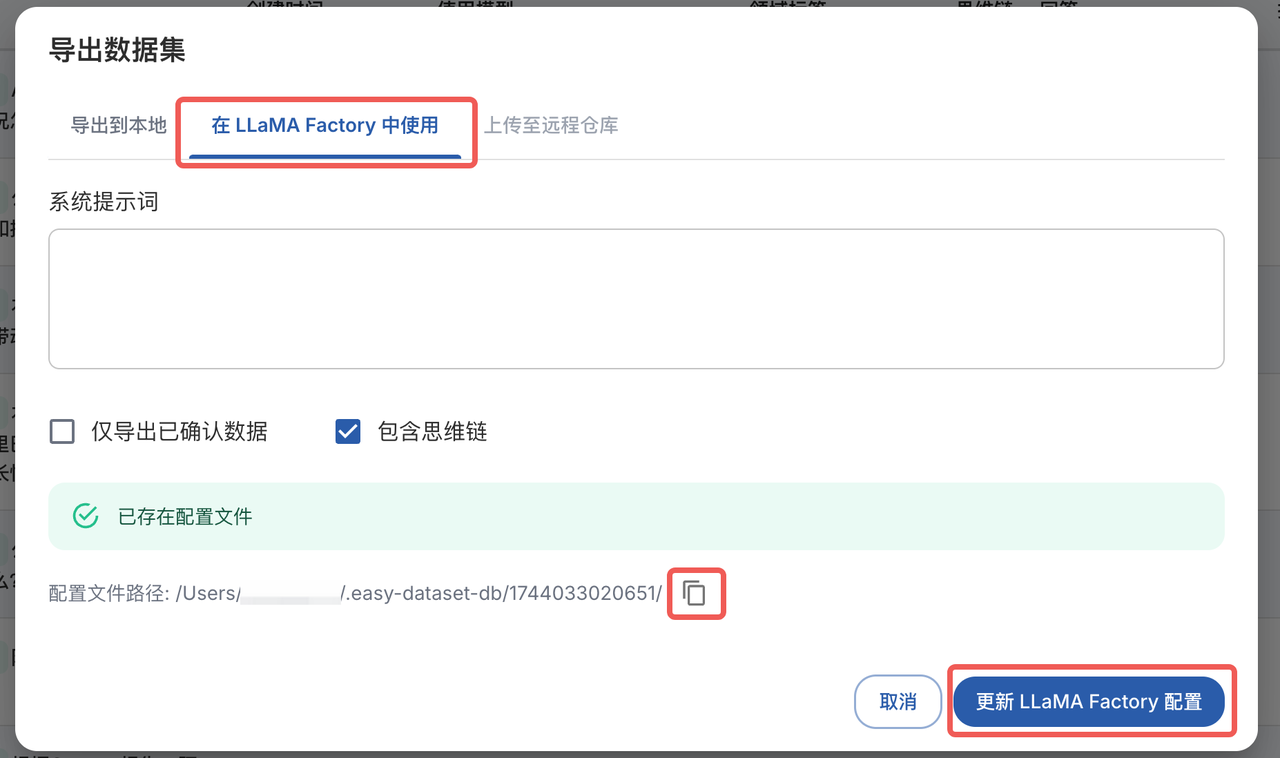
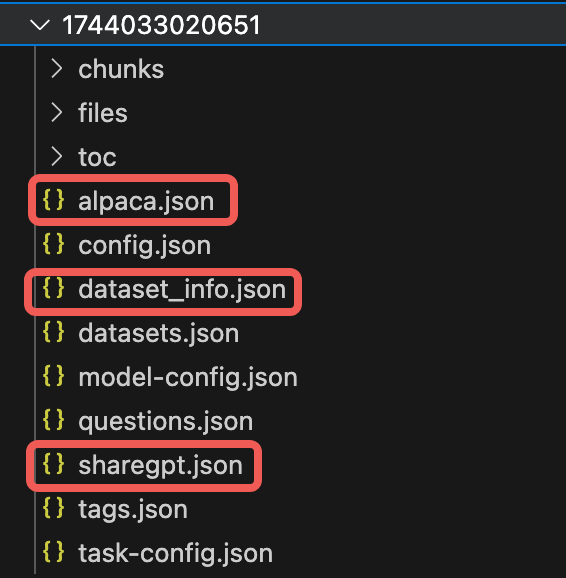
- 在配置文件路径对应的文件夹中可以看到生成的数据文件,其中主要关注以下三个文件
dataset_info.json:LLaMA Factory 所需的数据集配置文件
alpaca.json:以 Alpaca 格式组织的数据集文件
sharegpt.json:以 Sharegpt 格式组织的数据集文件
其中 alpaca 和 sharegpt 格式均可以用来微调,两个文件内容相同。
附录2-FastAPI封装后调用
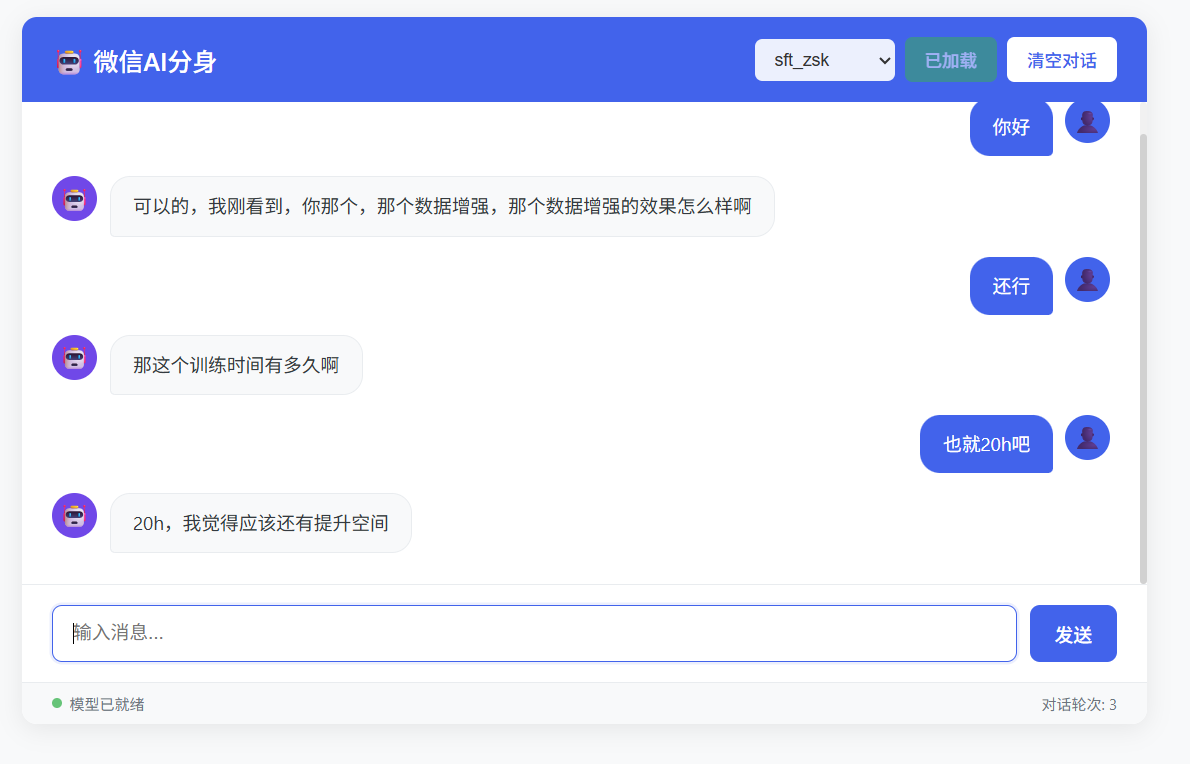
用python生态中的fastapi框架,可以很简单的快速搭建web调用的示例,一个后端apply.py封装好已经微调后的模型,进行调用,前端做一个非常简单的对话界面即可。目录结构:
1 | web_demo |
由于界面比较简单,直接在index.html中用HTML、css渲染、JavaScript交互即可。index篇幅过长,就不在这里列出代码,下面是后端apply.py的代码,直接对微调后的Qwen-huanhuan进行调用,封装给前端即可。
1 | from flask import Flask, request, jsonify, render_template |
最终的效果如下: